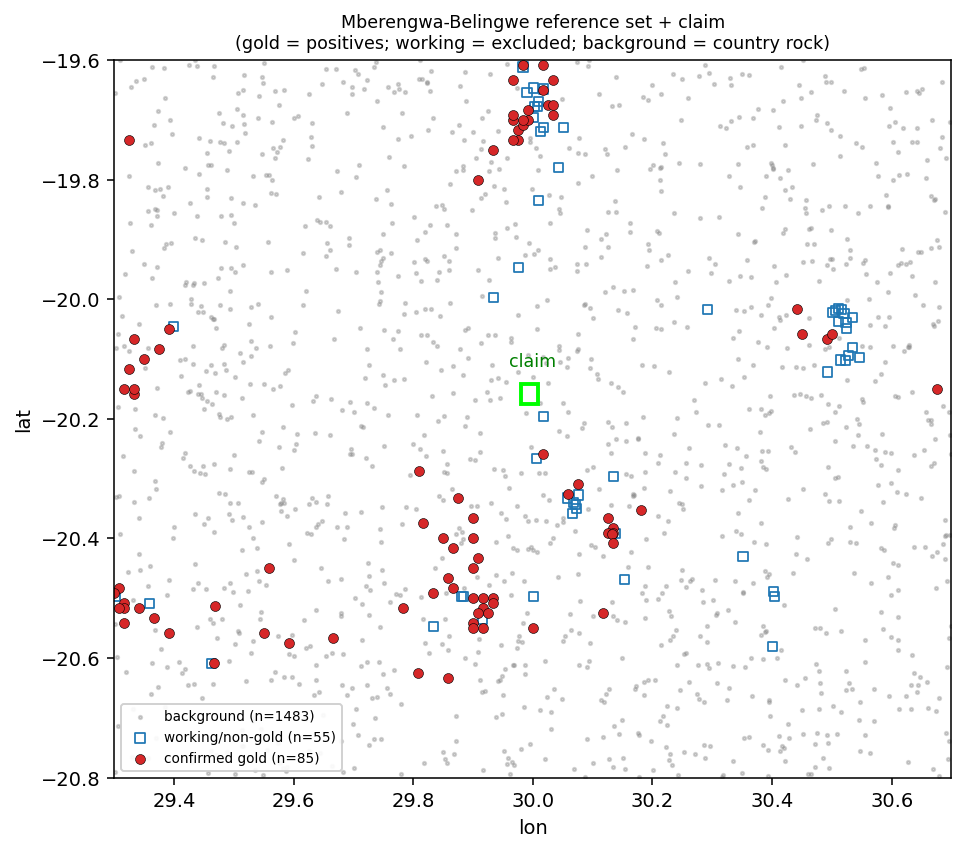
Does the claim look like known gold ground?
The one result in this study with measured skill. Every other arm here is a prioritization layer with no ground truth: an iron-oxide ratio, a structural lineament, a clay anomaly, each honestly labelled "we cannot tell you if it works, because there are no assays." This arm is different. It asks a question we can actually grade, and it earns a score.
The question: does a place's AlphaEarth satellite embedding resemble the embeddings at the belt's 85 confirmed gold occurrences more than it resembles random country rock? AlphaEarth compresses years of optical, radar, and elevation observation into a 64-number fingerprint per 10 m of ground. If gold deposits sit in ground that shares a fingerprint, a model trained on the known deposits should recognize an unseen one. We can test exactly that by hiding deposits and checking whether the model still finds them. It does.
Method
This arm reads the AlphaEarth Embedding Fields v1 annual mosaic directly
from its public Cloud-Optimized GeoTIFFs on Source Coop (@tge-labs/aef, CC-BY-4.0),
over plain HTTPS range requests through /vsicurl/. Each of the ~12 belt tiles (2024, UTM 35S + 36S)
is opened once at overview factor 8 (80 m effective), and sample points are then
indexed straight out of the in-memory arrays. The int8 embeddings are dequantised
as deq = (raw / 127.5)^2 * sign(raw), with the fill value mapped to NaN.
The recipe is research/mineral-prospecting/embedding-analog/prospectivity_aef.py.
How the analog is built
- Gold reference matrix. The 85 confirmed gold occurrences of the belt (Bartholomew/Blenkinsop ZGS inventory; the 55 Great-Dyke asbestos/chromium workings are excluded). Each is sampled as a 3x3-pixel (~240 m) window mean to absorb the ~0.5 km coordinate error in the inventory.
- Background matrix. 1,483 random belt points, each kept at least 1,500 m from every occurrence, so "background" means country rock, not undiscovered deposit.
- Model. A RandomForest (300 trees, max depth 12, balanced class weight) learns P(gold) directly on the raw 64-D embedding. A cosine-to-gold-prototype score is reported alongside as a transparent, model-free cross-check.
The validation: leave-one-out skill
This is the gate, and it is what makes the arm worth leading with. Hold each gold site out of training, refit the model, score the held-out site, and record where it lands relative to background. A site the model has never seen either still looks like gold (skill) or does not (no skill). Averaged over all 85, this is an honest out-of-sample test.
| Leave-one-out metric | Value (50 / 0.5 = chance) |
|---|---|
| Gold sites tested | 85 |
| Background points | 1,483 |
| Median held-out percentile | 99.12 |
| Mean held-out percentile | 96.16 |
| Fraction above the 50th percentile | 0.988 |
| Fraction above the 90th percentile | 0.894 |
| AUC, held-out gold vs background | 0.9608 |
The median held-out gold site lands at the 99th percentile of background, and held-out gold separates from country rock with AUC 0.96, where 0.5 is a coin flip and 1.0 is perfect. The AlphaEarth embedding analog generalises: an unseen gold site still looks like the known ones. This is the first measured skill anywhere in the study, and it is strong.
The claim verdict: intermediate (honest)
With a validated model in hand, we score a dense 80 m grid over the claim AOI and compare it to the background distribution.
| Claim metric | Value |
|---|---|
| Claim median P(gold) | 0.0388 |
| Background median P(gold) | 0.0167 |
| Gold (in-sample) median P(gold) | 0.7465 |
| Claim median percentile vs background | 71.5 |
| Fraction of claim exceeding the gold self-median | 0.0 |
| Cosine to gold prototype: gold / background / claim | 0.941 / 0.927 / 0.871 |
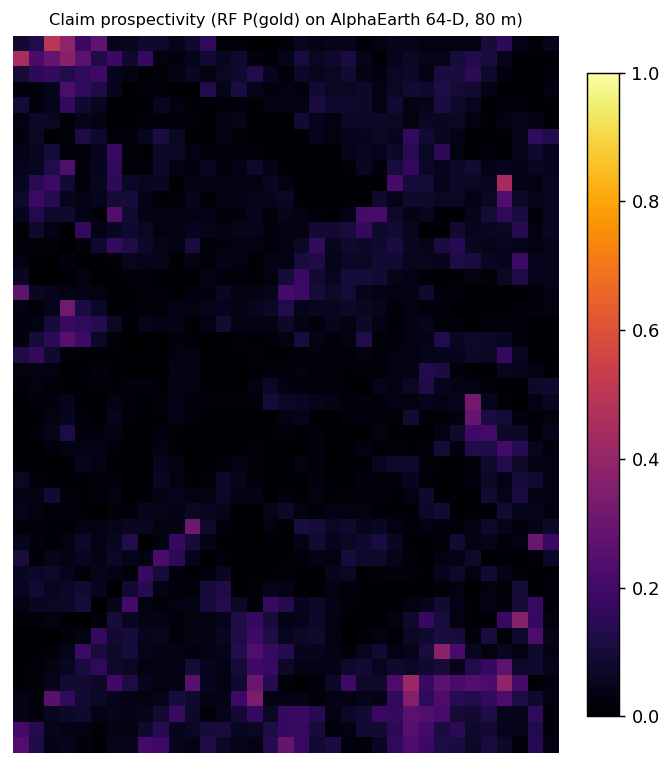
The verdict is intermediate. The claim's embedding sits at about the 71st percentile of background: above ordinary country rock, but far below the gold band (median P(gold) 0.039 for the claim, versus 0.017 for background and 0.75 for known gold). No clear resemblance either way. Not one cell of the claim grid reaches the median score of the known deposits.
That is a genuinely interesting non-answer. The claim is on the Great Dyke ultramafic margin, about 11 km from the nearest greenstone-belt gold, in a different lithological setting. A claim there reading above background, even modestly, is worth noting. But "above background, below gold" is exactly that, an intermediate resemblance score, and nothing more.
Caveats (the same honesty as everywhere else)
- Prospectivity heuristic, not detection. A high score is "looks like known-gold ground in the embedding," never "gold present."
- Coarse labels. The reference coordinates are ~0.5 km (gridded to ~30 arc-sec). The 240 m sampling window absorbs that, but sub-100 m targeting is not supported by these labels.
- Coarse sampling. The embedding is read at 80 m effective (overview factor 8), well above AlphaEarth's 10 m native resolution. Adequate given the ~0.5 km label precision, but it blurs fine boundaries.
- Single source. ~95% of the gold points come from one inventory (Bartholomew via Blenkinsop); little independent corroboration of individual points.
- Selection bias. The inventory is discovered and historically produced deposits. Undiscovered and sub-economic gold is absent, so the model learns the look of known deposits only.
- Indirect inference. AlphaEarth embeds surface and seasonality, not subsurface mineralisation. Any geological reading is one step removed.
Provenance
- Embeddings: AlphaEarth Embedding Fields v1 annual,
@tge-labs/aefon Source Coop (CC-BY-4.0), fetched via HTTPS range reads through/vsicurl/. - Gold reference: Bartholomew (1990), ZGS Mineral Resources Series 23, via Blenkinsop (2011), CC-BY. The 85 confirmed gold occurrences, with production and grade, are the same reference set plotted on the interactive map.
- Recipe:
research/mineral-prospecting/embedding-analog/prospectivity_aef.py; full run record inoutputs/loo_results.json.